大脑4D成像技术推动人工智能视听分析
当一个人的听觉和视觉不受损害且功能处于相对较高的水平时,人脑能够接收来自任何环境的各种视觉和声音,并无缝地让该人感知周围发生的事情。
但它是如何工作的呢?剧透警告:事情远比我们看到的复杂。
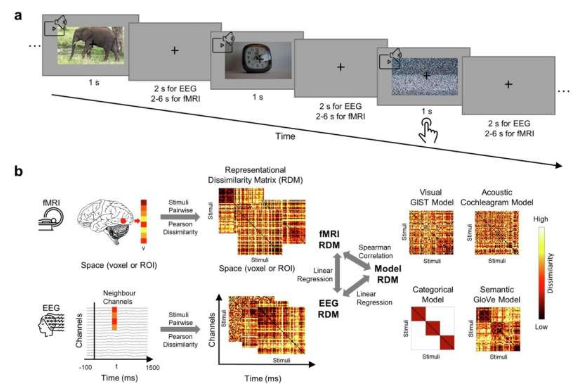
西方研究人员领导的一项新研究通过开发一种新的 4D 成像技术揭示了大脑如何处理多感官视听信息,其中时间是第四维。研究人员瞄准了大脑同时处理视觉和听觉输入时发生的独特互动。
计算机科学教授 Yalda Mohsenzadeh 和博士生 Yu (Brandon) Hu 使用功能性磁共振成像 (fMRI) 和脑电图 (EEG) 对研究参与者进行分析,以分析他们对 60 个视频片段和相应声音的认知反应。结果显示,大脑中的初级视觉皮层对视觉和低级听觉输入都有反应,而大脑中的初级听觉皮层仅处理听觉信息。
人工智能和机器学习专家 Mohsenzadeh表示,大脑的这种不对称或不均匀性对于构建更具生物学合理性的多感官神经网络具有重要意义。神经网络是一种教计算机处理数据的人工智能方法。
“最初,神经网络大致受到人类大脑的启发,但如今,人工智能并不一定会模仿人类大脑。他们更专注于基于尖端人工智能框架优化结果和相关任务,”西部神经科学研究所核心教员 Mohsenzadeh 表示。“我们有兴趣通过了解大脑的工作原理来制作更好的人工智能模型,因为我们仍然可以从大脑中获得一些新的想法。我们应该利用它们。”
该研究结果发表在《通信生物学》杂志上,可能会影响人工智能(AI)算法未来处理视听数据的方式,因为目前许多程序使用图像和视频来分析现实世界中的事物,如“猫”、“海滩”和“烤面包机”,而不是声音。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。